菜单
首页财产阐发评论ai正文 AI超节点时代的互换机革命 AI年夜模子参数范围增加,倒逼AI练习集群范围扩容,收集机能成要害。文章先容RDMA技能和InfiniBand及以太网之争,还有说起超节点发作与厂商抢滩AI互换机赛道相干环境。 2026-04-01 08:20 ·微信公家号:半导体财产纵横鹏程 AI投资人解读· AI年夜模子成长鞭策AI算力集群范围扩容,收集机能成要害。RDMA技能成冲破收集瓶颈方案,主流实现方案分三类。InfiniBand机能优但成本高,RoCE v2基在以太网,成本低、扩大性强。AI超节点发作,高端互换机需求年夜增,海内外厂商纷纷结构。· 行业竞争激烈,技能迭代快,可能致使产物快速过时供给链集中在少数厂商,可能带来供给危害。总结:AI互换机市场机缘年夜,但竞争激烈、技能迭代快且供给链集中,投资时需综合评估技能趋向、市场需求和厂商竞争力,紧密亲密存眷行业动态与危害因素。内容由AI天生,仅供参考
AI年夜模子参数范围连续增加,单卡算力与显存的物理上限,正倒逼AI练习集群范围连续扩容。于这场AI算力武备竞赛中,收集机能早已经成为决议集群算力开释效率的要害。对于在超年夜参数范围的AI模子而言,更高的收集带宽,可以或许直接年夜幅压缩模子练习的完成周期。
AI算力开释的技能底座:RDMA
要冲破AI集群的收集机能瓶颈,RDMA技能已经成为行业公认的解决方案,而这一切的出发点,源在GPU通用计较时代的通讯瓶颈破局。
GPU Direct RDMA是2009年由Nvidia及Mellanox配合研发的软硬件协同立异技能。其时GPU已经经从图形衬着转向通用计较(GPGPU),成为HPC的焦点加快器。GPU计较能力虽然于连续晋升,但由于集群中差别节点之间的GPU间传输数据,仍需要CPU卖力,通讯存于瓶颈,以是GPU的计较能力的上风受其拖累不克不及彻底阐扬,从而致使集群总体效率不高。NVIDIA其时清楚地熟悉到必需解决这个问题,以是最先与互助伙伴Mellanox一路摸索GPU与网卡的直接通讯的解决方案GPU Direct over InfiniBand。后续该技能方案逐渐成熟,并在2012年随Kepler架构GPU及CUDA 5.0一路发布,并被正式定名为GPU Direct RDMA。
于此以前,传统数据中央的数据传输,始终受困在TCP/IP架构的原生缺陷。于传统传输方案中,内存数据拜候与收集数据传输分属两套语义调集,数据传输的焦点事情高度依靠CPU:运用步伐先申请资源、通知Socket,再由内核态驱动步伐完成TCP/IP报文封装,终极经由过程NIC收集接口发送至对于端。数据于发送节点需要依次颠末Application Buffer、Socket Buffer、Transport Protocol buffer的屡次拷贝,达到吸收节点后,还有要颠末划一次数的反向内存拷贝,完成解封装后才能写入体系物理内存。
这类传统传输方式,带来了三个问题:一是屡次内存拷贝致使传输时延居高不下;二是TCP/IP和谈栈的报文封装端赖驱动软件完成,CPU负载极高,其机能直接成为传输带宽、时延等机能的瓶颈;三是运用步伐于用户态与内核态之间的频仍切换,进一步放年夜了数据传输的时延与抖动,严峻制约收集传输机能。
RDMA(Remote Direct Memory Access,长途直接内存拜候)技能,恰是为破解上述痛点应运而生。它经由过程主机卸载与内核旁路技能,让两个运用步伐可以或许于收集上实现靠得住的直接内存到内存数据通讯:运用步伐倡议数据传输后,由RNIC硬件直接拜候内存并将数据发送至收集接口,吸收节点的NIC则可将数据直接写入运用步伐内存,全程无需CPU与内核的深度参与。
依附这些特征,RDMA已经成为高机能计较、年夜数据存储、呆板进修等对于低延迟、高带宽、低CPU占用有严苛要求的范畴,焦点的互联技能之一。而RDMA技能和谈的尺度化,也为差别厂商装备的互联互通提供了同一规范,鞭策技能从观点走向范围化商用。今朝,RDMA主流实现方案分为三类:InfiniBand和谈、iWARP和谈,以和RoCE和谈(含RoCE v1与RoCE v2两个版本)。
跟着AI模子参数从数十亿级跃升至数万亿级,单GPU内存容量连续扩容的同时,办事器间的数据传输效率,已经成为决议体系扩大能力、模子练习方针可否实现的要害要素。RDMA技能的价值也愈发凸显,可否高效拜候其他办事器的内存与资源,直接决议了体系的可扩大性,而直接拜候远端内存的能力,能直接晋升AI模子的总体练习机能。恰是借助RDMA技能,数据才能快速送抵GPU,终极有用缩短功课完成时间(Job Completion Time,简称JCT)。
InfiniBand及以太网之争
于AI智算收集的成长过程中,机柜间互联最早采用成熟的以太网方案,而跟着低时延需求的进级,InfiniBand依附机能上风快速突起。作为原生RDMA和谈的代表,InfiniBand由NVIDIA子公司Mellanox主导鞭策,能提供低在2微秒的极低传输时延,同时实现零丢包,可谓RDMA范畴的机能*。
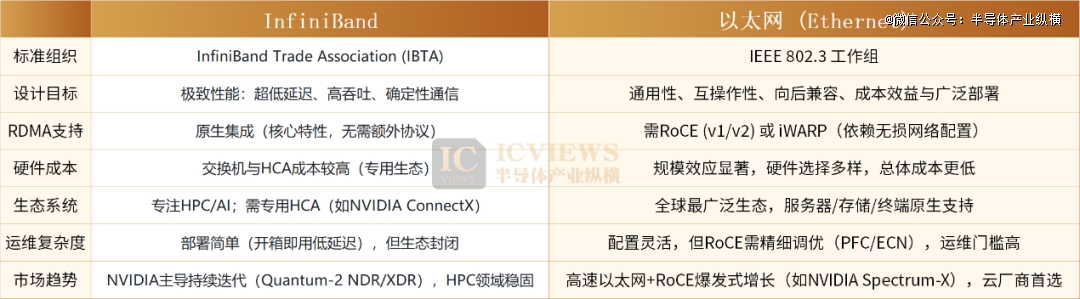
为了将InfiniBand的RDMA上风迁徙至以太网生态,RoCE和谈应运而生。此中RoCE v1仅能于二层子网内运行,而RoCE v2经由过程IP/UDP封装实现了跨子网路由,年夜幅晋升了部署矫捷性,只管约5微秒的时延仍高在原生InfiniBand,却让以太网具有了支撑AI练习高带宽、低延迟需求的能力。
为了撼动InfiniBand于AI范畴的主导职位地方,2025年6月,博通、微软、google等行业巨头结合推出UEC 1.0规范,旨于重构以太网和谈栈,使其机能迫近InfiniBand,标记着以太网对于InfiniBand倡议了周全还击。超以太网同盟(Ultra Ethernet Consortium,UEC)明确,UEC 1.0规范能于包罗网卡、互换机、光纤、电缆构成的全收集仓库层级,提供高机能、可扩大、可互操作的解决方案,从而实现多供给商无缝集成,加快全生态立异。该规范不仅适配以太网与IP的现代RDMA能力,还有撑持数百万级装备的端到端可扩大性,同时完全规避了供给商锁定的问题。
今朝,阿里巴巴、baidu、华为、腾讯等海内科技企业均已经插手UEC同盟,配合推进尺度落地。除了了介入全世界尺度化设置装备摆设,海内企业还有于同步研发自立可控的横向扩大架构,均以低延迟、零丢包为焦点方针,直接对于标InfiniBand的机能体现。
从财产落地的维度来看,两条技能线路的好坏势十分清楚。RoCE v2方案依托以太网架构,不仅具有RDMA高带宽、低时延的传输机能,还有拥有极强的装备互联兼容性与适配性,部署矫捷且成本上风显著。比拟InfiniBand,基在以太网的RDMA方案,于低成本、高可扩大性上拥有巨年夜上风。
收集可用性直接决议GPU集群算力的不变性,而AI技能的发作,正鞭策数据中央互换机向更高速度连续迭代。AI年夜模子参数目的指数级增加,带来了算力需求的范围化晋升,但年夜集群其实不等同在年夜算力。为了压缩练习周期,年夜模子练习遍及采用漫衍式练习技能,而RDMA恰是绕过操作体系内核、降低卡间通讯时延的焦点,今朝主漂泊地的恰是InfiniBand与RoCE v2两年夜方案。此中InfiniBand方案时延更低,但成本偏高,且供给链高度集中在英伟达。按照Dell‘Oro Group的猜测,到2027年,以太网于AI智算收集的市场占比将正式逾越InfiniBand。
超节点发作,高端互换机迎来黄金成长期
跟着AI 年夜模子参数范围迈入万亿量级,算力需求已经从纯真 GPU 重叠,转向全维度体系架构重构。受单芯片物理功耗密度、互连带宽和内存容量瓶颈制约,算力增加边际效益连续递减。当前研究与工程实践均注解,体系级协同架构(如高带宽域互联)是冲破单芯片机能上限的重要技能路径,其底子动因于在单芯片物理极限已经成为制约算力成长的焦点瓶颈。
当模子范围远超单芯片算力与显存容量,传统漫衍式练习面对通讯开消激增、算力使用率年夜幅下滑等难题。于此配景下,依托高速无损互联技能,将数十以致上百颗GPU 芯片逻辑整合为同一计较单位,形成对于外等效的 “超等计较机”,已经成为全世界主流 AI 基础举措措施厂商与科研机构公认的下一代算力架构冲破标的目的。
AI 超节点的发作,为互换机市场打开全新增量空间。相较在传统办事器,AI 办事器新增 GPU 模组,需经由过程专用网卡与办事器、互换机实现高效互联,完成节点间高速通讯。这使患上 AI 办事器组网于传统架构基础上,新增后端收集(Back End)层级,单台办事器收集端口数目显著晋升,直接拉动高速互换机、网卡、光模块、光纤光缆等全财产链需求。
与此同时,超节点范围化部署,加快收集架构横向扩大(Scale out)。万卡、十万卡以致百万卡级另外超年夜集群组网,催生海量高速互换机需求。跟着 AI 模子参数连续扩容,集群范围从百卡、千卡级快速向万卡、十万卡级跃迁,鞭策组网架构从 2 层向 3 层、4 层连续演进,进一步放年夜高速互换机市场缺口。
全世界AI财产的高速成长,让AI集群收集对于组网架构、收集带宽、收集时延提出了史无前例的严苛要求,也鞭策以太网互换机这一焦点通讯装备,朝着高速度、多端口、白盒化、光互换机等标的目的连续迭代进级。而以太网自己深挚的财产根底与重大的生态厂商声势,也让其于AI收集中的市场占比拥有连续晋升的空间。只管今朝InfiniBand依附低延迟、堵塞节制、自顺应路由等机制,仍主导着AI后端收集市场,但跟着以太网部署方案的连续优化,以和超以太网同盟的生态加快完美,将来以太网方案的市场占比将连续爬升,直接动员以太网互换机的需求增加。
全行业入局,海内外厂商抢滩AI互换机赛道
AI互换机的巨年夜市场机缘,吸引了全世界科技巨头与海内厂商的周全结构,从芯片到整机、从传统装备商到互联网企业,一场缭绕AI互换机的技能与市场争取战已经然打响。
国际巨头中,英伟达的结构最为激进。其推出的Spectrum-x平台,是一套专为超年夜范围集群场景优化的以太网方案,依附这一产物,英伟达仅用不到三年时间,便于互换机这一传统IT赛道实现了跨界冲破。同时,英伟达已经将下一代Rubin AI平台周全转向CPO(共封装光学)架构,并公布进入量产阶段,让CPO从试验室观点,正式成为将来AI数据中央的“尺度配置”。
博通也于去年推出了全世界*102.4 Tbps 互换机芯片 Tomahawk 6。该系列单芯片提供 102.4 Tbps 的互换容量,是今朝市场上以太网互换机带宽的两倍。Tomahawk 6 专为下一代可扩大及可扩大 AI 收集而设计,经由过程撑持 100G / 200G SerDes 及共封装光学模块(CPO),提供更高的矫捷性。它提供业界最周全的 AI 路由功效及互连选项,旨于满意拥有跨越一百万个 XPUs 的 AI 集群的需求。
海内传统装备厂商也快速跟进,接连推出旗舰级产物。
华为在2025年发布了两款旗舰产物:业界最高密的128×800GE 100T盒式以太互换机CloudEngine XH9330,依附行业*的高密端口设计,冲破了AI集群的范围上限;业界*128×400GE 51.2T液冷盒式以太互换机CloudEngine XH9230,助力企业打造绿色节能、超年夜范围的全液冷算力集群。
紫光股分旗下新华三,在2024年率先发布1.6T智算互换机H3C S98258C-G,撑持全光收集3.0解决方案,单端口速度冲破1.6T,整机互换容量达204.8T,可满意3.2万台AIGC节点的通讯需求。该产物搭载自研智算引擎,时延可低至0.3微秒,经由过程了google等国际客户的验证,成为其OCS整机焦点供给商。此外,公司还有推出了全世界*51.2T 800G CPO硅光数据中央互换机,为1.6T产物的技能迭代奠基了基础。
锐捷收集完成为了基在CPO技能的51.2T互换机商用互联方案演示,该方案依附超高集成度、显著的能效晋升与可维护性设计,*适配AI练习和超年夜范围计较集群的高速互联需求,为将来800G及1.6T收集进级提供了可行路径。其51.2T CPO互换机采用博通Bailly 51.2Tbps CPO芯片,于4RU空间内实现了128个400G FR4光互换端口,年夜幅晋升了装备端口密度与带宽容量,焦点亮点于在经由过程光引擎与互换芯片的共封装,年夜幅缩短电互联路径,降低旌旗灯号衰减与传输功耗。
复兴通信推出了国产超高密度230.4T框式互换机,以和全系列51.2T/12.8T盒式互换机,机能处在行业*程度,已经于运营商、互联网、金融等范畴的百/千/万卡智算集群实现范围商用。
除了了传统互换机厂商,互联网企业也纷纷下场,开启了自研互换机的进程,成为赛道中不成轻忽的主要气力。
腾讯早于2022年便启动了CPO互换机的研发,同年推出并点亮业界*25.6T CPO数据中央互换机——Gemini。该产物集成12.8T光引擎,提供16个800G光接口,残剩12.8T互换容量经由过程面板32个QSFP112可插拔接口提供。
字节跳动于火山引擎正式上线102.4T自研互换机,以此支撑新一代HPN 6.0架构,可满意十万卡级GPU集群的高效互联需求。该互换机实现全端口LPO撑持,于4U空间内部署了128个800G OSFP端口。
阿里巴巴于云栖年夜会展出了自研的102.4T国产互换机,率先将3.2T NPO技能运用在新一代国产四芯片互换机。该装备单机集成4颗25.6T国产互换芯片,总互换容量达102.4T,还有可经由过程进级至4×102.4T芯片,光滑演进至409.6T平台。
比拟线性驱动可插拔光模块(LPO),近封装光学(NPO)能提供更高的带宽密度,同时降低对于主芯片SerDes机能的要求,更利在财产生态成长;而比拟共封装光学(CPO),NPO采用尺度LGA毗连器,保留了光模块的开放解耦特征,防止了主芯片与光引擎的绑定,更容易被终端用户采取。
为何互联网企业要做互换机?
互联网企业纷纷下场自研互换机,并不是偶尔,而是技能趋向与市场需求的配合驱动。
技能层面,互换机白盒化的成长,为互联网企业自研提供了基础。白盒互换机实现了硬件与软件的解耦,硬件由开放化组件组成,软件则可由用户或者第三方自由选择、定制,具有高矫捷性、高可扩大性、低采购与运维成本的上风,今朝已经于互联网厂商与运营商收集中广泛运用,财产生态日益成熟。锐捷收集作为白盒互换机范畴的初期结构者,便与阿里、腾讯、字节跳动等互联网企业深度互助,经由过程JDM(结合设计制造)模式介入下一代互换机研发,2024年接连中标多家头部互联网客户的研发标,鞭策白盒互换机于互联网数据中央的范围化部署。而白盒互换机的软硬件解耦特征,年夜幅降低了自研的技能门坎,同样成为年夜型互联网企业降低建网成本的要害。
市场层面,超年夜范围数据中央运营商面对着与传统企业彻底差别的收集需求:一方面,阿里、腾讯、字节等企业拥有数万甚至数十万级的办事器范围,对于收集的可扩大性、可运维性有*要求;另外一方面,AI练习集群特别是万卡级GPU集群,对于收集的低延迟、高带宽有着严苛的定制化需求。传统互换机厂商提供的尺度化产物,难以彻底匹配这些个性化、*化的营业需求,终极促使互联网企业走向自研之路。
而自研互换机不仅能深度适配自身营业场景,实现收集能力的定制化优化,又能年夜幅降低集群设置装备摆设的整体拥有成本(TCO),于AI算力武备竞赛中,把握收集底层能力的自动权。
【本文由投资界互助伙伴微信公家号:半导体财产纵横授权发布,本平台仅提供信息存储办事。】若有任何疑难,请接洽(editor@zero2ipo.com.cn)投资界处置惩罚。
-ng28(南宫)相信品牌的力量