菜单
首页财产芯片半导体正文 SRAM,更难了 SRAM扩大不太可能重现旧日的光辉,这象征着必需寻觅替换方案。3D重叠技能可能会变患上越发普和,特别是于价格降落的环境下。 2026-03-29 09:37 ·微信公家号:半导体行业不雅察 AI投资人解读· SRAM是计较体系主要部门,但容量及机能晋升阻滞,成本增长,影响各范畴。虽有改良但数据难证,2nm技能不明。人工智能下拜候模式变化成限定因素。 · 行业竞争加重,SRAM微缩面对物理及工艺误差极限,进步前辈制程节点问题更严峻,影响成本与机能。新型存储器虽有潜力但不克不及彻底替换SRAM。 总结:SRAM成长受限,内存瓶颈凸显,需寻觅替换方案,今朝3D重叠技能有潜力但未成熟,行业面对诸多挑战,投资需审慎评估危害与潜力。内容由AI天生,仅供参考
SRAM 是所有计较体系的主要构成部门,但它未能跟上逻辑电路的扩大程序,造成为了愈来愈棘手的问题,而这些问题于已往五年中变患上越发严峻。
早于1990年,亨尼西及帕特森就出书了《计较机系统布局:量化要领》一书。作者其时就已经清晰地熟悉到,内存容量及机能将成为将来处置惩罚能力成长的要害瓶颈(见图1)。几十年来,硬件架构一直于逃避这个问题,凡是利用SRAM作为缓存,并辅以容量更年夜的片外DRAM。虽然这使患上内存看起来更年夜,但速率往往慢患上多。这就是所谓的“内存墙”。
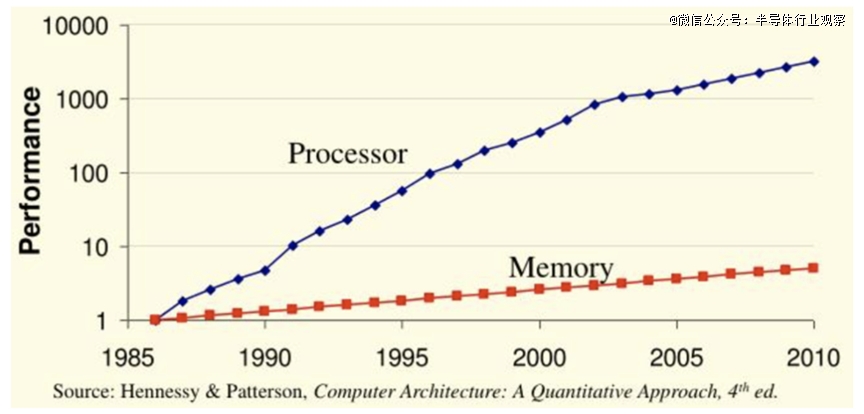
图 1:内存墙的初期辨认
于所有计较情势中,步伐及数据都存储于静态随机存取存储器(SRAM)中。处置惩罚器从该存储器中读取指令。这些指令告诉处置惩罚器要对于一样存储于该存储器中的数据履行哪些操作。
SRAM 比处置惩罚器内部姑且存储数据的寄放器更自制。虽然寄放器单位可使用与 SRAM 不异数目的晶体管,但寄放器利用更昂贵的解码及拜候机制,这类机制没法跟着寄放器组巨细的增长而扩大。
SRAM 存储器由一系列存储单位构成,周围环抱着电路,这些电路可以或许以随机方式读取及存储数据。于很多环境下,周围的逻辑电路是半定制的,由于它会跟着存储阵列范围的增年夜而变化。事实上,很多存储器速率的晋升都来自在这些电路的改良,而不是存储阵列自己的改良。
跟着SRAM容量及机能的晋升险些阻滞不前,将来远景愈发黯淡。这象征着,跟着制程节点的不停缩小,不异容量的SRAM所占用的芯单方面积比例却愈来愈高。跟着愈来愈多的芯片到达光刻工艺的极限,这类状态难以蒙受,制造商不能不比以往更多地依靠外部存储器。而外部存储器的速率要慢患上多。
于人工智能时代,拜候模式发生了变化,这也迅速成为重要的限定因素。
台积电认可SRAM微缩存于一些问题,但该公司声称其新的2nm纳米片技能(见图2)已经有所改良。然而,很难得到确实的数据来撑持这一说法。已往,现实成果往往低在年夜范围运用前宣布的数据。
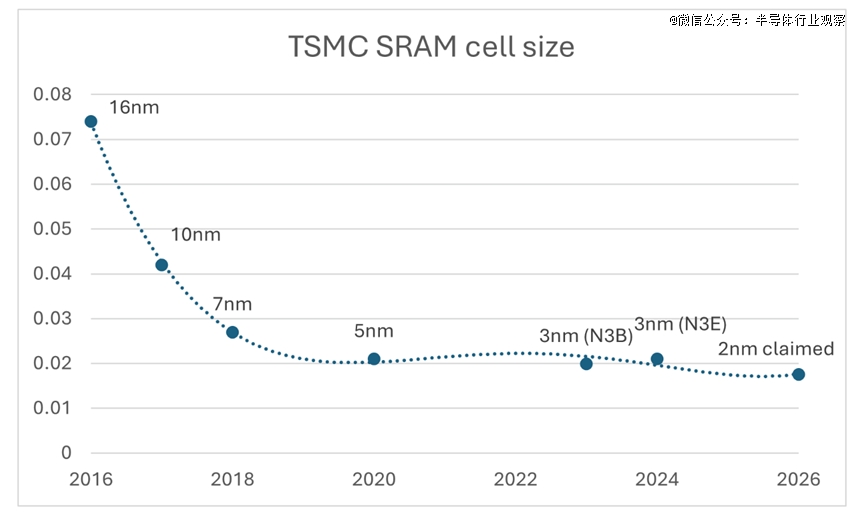
图 2:台积电 SRAM 单位尺寸(数据来自公然渠道)
虽然这可以被视为内存问题,但归根结柢是计较问题。“机能并不是受限在计较能力,” Eliyan的首席履行官兼结合开创人 Ramin Farjadrad 暗示,“于许多环境下,年夜大都功效的处置惩罚器使用率只有 20%,甚至更低。机能重要受限在内存及内存带宽。这就是所谓的内存墙。”
SRAM 微缩
人们很轻易认为,当晶体管尺寸缩小时,由六个晶体管构成的 SRAM 单位的尺寸及机能也会随之降低。“SRAM 微缩阻滞不前,是由于传统的 6T 位单位到达了物理极限及工艺误差极限,” Synopsys嵌入式存储器 IP 首席产物司理 Daryl Seitzer 暗示。“SRAM 位单位的设计初志是实现高密度存储,但它存于一个固有的缺陷,即读写需求彼此冲突。拜候晶体管与存储晶体管之间存于竞争,这类竞争需要细心均衡,并思量工艺误差。跟着几何尺寸的缩小,工艺误差对于位单位读写特征的影响比例会愈来愈年夜。”
问题远不止在此。“跟着制程节点的缩小,静电节制及随机颠簸成为重要制约因素,拦阻了单位面积的响应缩小,” Arteris产物治理高级司理 Andre Bonnardot 暗示。“此外,因为导线电阻及位线电容的增长,SRAM 的速率已经经到达瓶颈,而 Vdd 于近来的制程节点中险些没有降低。逻辑电路可以经由过程器件及布线方面的立异继承缩小尺寸,但 SRAM 却没法做到这一点。”
跟着制程节点的更新,这些问题愈发严峻。“于进步前辈的2nm和如下制程工艺上,SRAM位单位的密度晋升幅度已经降至不足15%。” Cadence硅解决方案集团研究员Gopi Ranganathan暗示,“这远低在咱们于65nm到5nm工艺技能迭代历程中所履历的50%到100%的逐代缩小幅度。这类降落可归因在进步前辈制程节点上器件、栅极触点、MEOL以和V0/V1的尺寸极为狭小,而进一步成心义的尺寸缩小遭到东西的限定以和硅良率的制约。”
其影响是成本更高、机能更低。“重要体现为存储器密度扩大速率掉队在传统存储器,” Quadric首席技能官 Nigel Drego 暗示。“每一平方毫米门数(Gate/妹妹²)的成长速率跨越了每一平方毫米兆字节数 (MB/妹妹² )。此外,因为路线延迟及物理定律与 SoC 设计职员的需求不符,拜候速率也遭到影响。然而,巧妙的架构调解可以减缓逻辑及 SRAM 速率之间的依靠性。”
自 20 世纪 80 年月以来,这类差距一直于扩展,那末如今的计较机技能与二十年前比拟怎样呢?Eliyan 公司的 Farjadrad 暗示:“计较机或者处置惩罚器的机能晋升了近五个数目级。但这些计较机需要处置惩罚来自内存的数据。内存带宽甚至没有晋升 100 倍,是以,计较机现实处置惩罚或者可以或许处置惩罚的数据量与现实输入的数据量之间存于跨越 1000 倍的差距。”
这不单单是前沿人工智能技能的问题。终极,它将影响到所有范畴——甚至包括小型微节制器(MCU)及微处置惩罚器(MPU)——特别是于人工智能向边沿运用成长的历程中。“于某种水平上,它变患上没法扩大,届时SRAM将盘踞芯片总面积的更年夜比例,”瑞萨电子首席产物营销司理Kavita Char暗示。“这是咱们必需思量的问题。这也会影响芯片用户,由于他们必需思量哪些功效可以于芯片上实现,以和什么时候需要利用外部存储器。跟着芯片几何尺寸的缩小,成本也会愈来愈高。”
今朝尚不清晰N2的位单位面积是否比上一代产物更优。“SRAM近期的机能晋升重要患上益在逻辑电路尺寸的缩小,并将其运用在SRAM宏的解码及节制电路,”Synopsys嵌入式存储器IP高级产物司理Rahul Thukral暗示。“这需要设计上的立异,而咱们可以或许于位单位尺寸未缩小的环境下实现如许的面积上风。跟着环栅(GAA)技能的改良以和器件宽度节制矫捷性的提高,估计将来机能将进一步晋升。GAA晶体管可以或许提供更好的静电节制,从而降低泄电并改善读写机能,估计还有将带来更多改良。对于在最初的2nm工艺,存储器面积正于改善,此中年夜部门机能晋升来自解码及数据通路电路中的逻辑器件。然而,跟着GAA晶体管的进一步缩小,位单位面积有望进一步缩小,估计于后续节点中位单位面积将进一步降低。”
Arteris公司的Bonnardot暗示:“咱们认为SRAM扩大速率的放缓正处在体系架构的拐点。当内存密度增加放缓时,简朴地增长缓存就变患上不经济了。”
对于软件的影响
对于软件的影响规模广泛,挑战了持久以来“软件出产力是优化最主要的方针”这一不雅念。如今,很多范畴都于质疑这一不雅点,特别是于愈来愈多的产物走向软件界说化以后。“依靠在海量当地SRAM及多层快速缓存的处置惩罚器架构将遭到*的影响,”Quadric公司的Drego暗示。“CPU没法防止这些硬件密集型的内存架构,由于咱们手机、条记本电脑及数据中央中的CPU被设计用在运行具备非布局化内存援用的随机用户代码,并同时处置惩罚数十个线程。”
对于在这种公司而言,选择余地未几。“SRAM 此刻盘踞了芯单方面积及成本的更年夜比例,”Bonnardot 暗示。“年夜型寄放器文件及缓存条理布局再也不可以或许自由扩大,这加年夜了对于芯片尺寸、良率、能效及数据传输效率的压力。这使患上瓶颈从计较密度转移到了内存架谈判互连效率。软件必需假设内存的条理布局越发繁杂,速率也越发分离。局部性、分块、分区及流量可猜测性变患上越发主要,而延迟差异则成为体系级机能的限定因素。”
人工智能也没法挣脱这些问题。“跟着人工智能模子范围及上下文长度的增加,内存带宽及片上缓存成为机能瓶颈,”Synopsys公司的Seitzer暗示。“这于LLM推理中体现患上尤为较着,键值缓存带宽成为瓶颈。是以,软件必需优化数据局部性、内存感知调理、量化、稀少性及内存分层,由于计较能力的晋升已经没法填补内存扩大速率的迟缓。”
人工智能架构的一些差异可以被使用。“人工智能引擎,特别是人工智能推理处置惩罚器,可以永劫间处置惩罚布局优良的代码,其运行时间比频仍切换使命的CPU长几个数目级,”Drego说道。“智强人工智能架构将内存治理推入离线编译器,这些编译器可以调理显式的代码驱动的DMA传输,用在传输人工智能模子的权重及激活值。整小我私家工智能推理处置惩罚引擎均可以构建成不需要任何数据缓存的架构。这减轻了利用最高速率、最高功耗的SRAM来设计分层缓存、缓存标签及转换缓冲区的压力。跟着愈来愈多的事情负载依靠在人工智能模子,进步前辈SoC芯单方面积中愈来愈年夜的部门可以免SRAM密度/速率瓶颈,从而将这一设计挑战限定于要害的CPU子模块中。”
也许业内并不是所有人都留意到了这一点。“对于在人工智能模子来讲,有一个叫做算术强度的观点,”Eliyan公司的Farjadrad说道,“它指的是处置惩罚器于内存上运行的函数或者操作的数目。遗憾的是,近期人工智能模子的算术强度远低在以往。是以,从内存处处理器的带宽需求更年夜了。”
3D SRAM
假如 SRAM 没法扩大,那末利用最昂贵的工艺节点就毫无心义。今朝,人们愈来愈偏向在将 SRAM 集成到芯片上,并安装于处置惩罚器之上。Cadence 公司的 Ranganathan 暗示:“SoC 设计职员正于摸索解耦方案,行将极少量 SRAM 放置于采用*进工艺节点设计的芯片上。最要害的需求是 CPU/GPU/AI 事情负载,例如 1 级、2 级甚至 3 级。于这类环境下,更年夜的 SRAM 容量(例如 4 级)则放置于更早工艺节点的芯片上,从而降低每一个晶体管的成本。更快的芯片间通讯链路及更小的互连间距的呈现,使患上多存储器条理布局的集成越发轻易,从而于合理的延迟影响降落低成本。”
今朝,这是一种成本昂扬的解决方案。“因为封装成本高、散热繁杂且尺度化水平有限,基在3D及芯片组的SRAM今朝仅合用在高端AI/HPC芯片,”Seitzer暗示。“如今,SRAM密集型芯片组仍旧集中于高端装备中,需要经由过程定制解决方案将SRAM与其他高价值IP集成于一路。短时间内实现低成本、面向公共市场的SRAM芯片组好像不太可能。”
但那一天也许终会到来。“Chiplets提供了一种*的解决方案,可以或许以更低的功耗实现更高的带宽,”Farjadrad说道。“每一个人都需要让它阐扬作用,这就是为何整个行业云云存眷解决这些挑战的缘故原由。这才是打破机能瓶颈的路子,不仅合用在2.5D,也合用在3D。”
替换方案
每一当内存呈现问题时,人们总会会商可以用哪些新型内存技能来替换SRAM。“新兴技能于某些特定环境下有所帮忙,但它们其实不能彻底替换SRAM,”Bonnardot说道。“将来的年夜大都体系将会利用更多层级的内存,而不是更少。”
将来的体系架构也可能有所差别。“内存计较或者近内存计较的观点,恰是人工智能的成长标的目的,这象征着传统模子将会发生一些变化,” Baya Systems首席商务官Nandan Nayampally暗示。“传统模子缭绕着重大的计较引擎构建,这些引擎试图从相对于接近内存的位置提取数据。是以,体系将连续演进,最先利用差别的存储器,由于咱们终极可以说SRAM已经经没法扩大。这是一种对待问题的方式。另外一种对待问题的方式是,咱们今朝利用SRAM的方式是否已经经到达了架构上的极限?我认为后一种环境更为较着。Cerebras于晶圆级运用方面迈出了主要一步,行将更多的存储器集中于芯片上,从而转变了一些限定。”
纵然有了这些前进,单个芯片上可容纳的模子尺寸仍旧有限。“这就引出了一个重要问题:‘于一片晶圆上毕竟能高效地实现甚么?’ 假如最先重叠晶圆或者出产更年夜的晶圆,这类架构还有能继承正常扩大吗?还有是终极会碰到一样的限定?所谓的‘内存墙’并不是一次性的障碍,”纳亚姆帕利说道。 “假如架构连结稳定,模子尺寸的每一一次增多数会带来新的障碍。是以,设计决议计划必需着重思量体系的可扩大性,从单芯片到多芯片以致更年夜规模。最初,咱们看到的是CPU集群。厥后是芯片组集群。再厥后,成长到板级集群。如今,扩大象征着要让整个机架作为一个同一的计较资源运行,甚至更进一步。于每一个阶段,不管是纳米级、毫米级、厘米级、米级还有是千米级,城市呈现新的挑战。终极,怎样划分及治理资源决议了你降服这些重复呈现的障碍的能力。”
新型存储器也正于站稳脚根。“一些新兴的嵌入式存储器确凿揭示出了真实的市场吸引力,特别是于SRAM或者嵌入式闪存难以胜任的范畴,”Seitzer说道。“例如,MRAM具备优良的可扩大性、低走漏、高经久性,有望代替SoC中的部门嵌入式闪存/SRAM。ReRAM因为易在集成及成本较低,正被愈来愈多地采用,成为一种更经济高效的嵌入式非易掉性存储技能。这些技能可以加强而非代替L1/L2缓存中的高机能SRAM,但它们有望代替某些节制器、MCU及加快器中的嵌入式存储器。”
高带宽内存 (HBM) 备受存眷,它显著晋升了 DRAM 的带宽。HBM 由多层 DRAM 重叠而成,其底层传统上是与处置惩罚器直接毗连的芯片级物理层 (PHY)。因为底层芯片采用了与位单位层不异的工艺技能——一种针对于存储单位而非逻辑电路优化的工艺——是以其功耗密度及热密度遭到限定。假如将底层芯片的工艺进级为针对于逻辑电路优化的工艺,则可以撑持更多潜于功效并实现更高的机能。
“经由过程这类方式,咱们可以于HBM基片及GPU之间实现更高带宽的芯片间接口,”Farjadrad说道。“咱们可以使用基片另外一侧的残剩带宽来毗连其他装备。这些分外装备可所以另外一排HBM,从而使GPU可拜候的HBM容量翻倍。或者者,也能够将其用在I/O芯片组,以提供更高的外部带宽,或者者二者兼而有之。”
此外,缓存治理方面也有了更年夜的空间。“于SRAM扩大再也不主动的时代,架构效率,特别是于布局及一致性层面,成了每一平方毫米机能及每一瓦机能的要害地点,”Bonnardot说道。“经由过程智能地治理缓存位置及流量举动,缓存可以于不可比例增长SRAM面积的环境下,提供充足的内存容量及带宽晋升。”
结论
内存瓶颈日趋凸显,并且短时间内险些没有转变的迹象。SRAM 扩大不太可能重现旧日的光辉,这象征着必需寻觅替换方案。3D 重叠技能可能会变患上越发普和,特别是于价格降落的环境下。但今朝还有没有万全之策。假如高速内存成为计较能力的瓶颈,那末计较就必需更有用地使用现有内存。
【本文由投资界互助伙伴微信公家号:半导体行业不雅察授权发布,本平台仅提供信息存储办事。】若有任何疑难,请接洽(editor@zero2ipo.com.cn)投资界处置惩罚。
-ng28(南宫)相信品牌的力量