菜单
首页财产阐发评论ai正文 电费只占5%,谁于真正吃失算力成本? 沐曦披露数据中央成天职析图,显示电费于总成本中占比低,GPU才是年夜头。国产GPU机缘与挑战并存,2025年下半年多家公司加快国产算力集群部署。 2026-03-30 08:11 ·微信公家号:半导体财产纵横周遭 AI投资人解读· 沐曦数据中央成天职析显示,1GW数据中央四年总拥有成本550亿美元,GPU芯片占250亿,电费仅占5%。GPU短时间内难降价,因其成本组成繁杂,相干环节被少数供给商垄断。· 2025-2026年是国产GPU机缘期,但国产GPU于机能、软件生态、供给链方面存于挑战。数据中央可经由过程液冷、优化收集存储等降低成本,不外需垂直整合能力。总结:数据中央成本布局中GPU占比年夜,国产GPU迎来机缘但面对挑战,数据中央优化成本需多方面努力,投资要综合考量各因素。内容由AI天生,仅供参考
近期,沐曦于行业分享中披露的一组数据中央成天职析图表,激发了业内子士的广泛存眷。
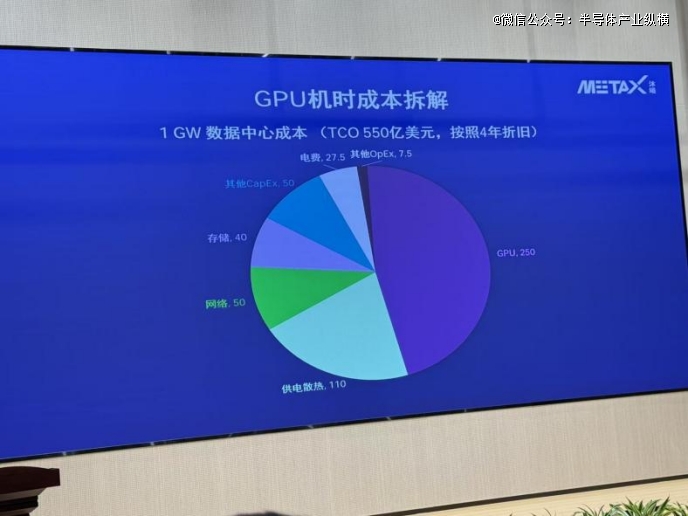
这张图拆了一座1GW数据中央的账——总拥有成本550亿美元,按四年折旧摊下来,GPU芯片占了250亿,供电散热110亿,收集50亿,存储40亿。电费呢?27.5亿。占比5%。
就这么一张图,把一个于圈里传播了小两年的“夸姣叙事”推翻了。以前总有人说,中国电价比泰西自制,AI时代这就是咱们的资本。年夜模子那末耗电,电价低就是连续上风。可沐曦这张图告诉你的倒是另外一回事:于超年夜范围算力中央的成本布局里,电费于总体TCO 中占比很低,对于总成本影响有限。真实的年夜头,是你底子绕不开的那块GPU。
0一、一座550亿美元的数据中央,钱都花哪儿了
咱们先把这个账算细一点。
图里的550亿美元,是基在一座1GW的数据中央做的全周期测算,周期是四年。为何是四年?由于GPU的折旧周期就这么长,甚至许多互联网年夜厂现实折旧周期更短——三年甚至两年半。这不是管帐上的守旧处置惩罚,而是技能迭代的实际:新一代GPU出来,老一代的单元算力成本及能效比就马上掉去竞争力。
于这550亿里,GPU采购250亿,占比45%。这还有只是买芯片的钱。供电及散热体系110亿,占比20%。这部门听着像是“基础举措措施”,但现实上一泰半成本是被GPU的功耗逼出来的——一颗H100功耗700瓦,B系列下一代直奔1000瓦以上,几万张卡堆于一路,供电及散热体系的繁杂水平远超传统数据中央。
收集50亿,存储40亿。这两块加起来90亿,占比16%。超年夜范围集群里的收集,不是我们家里用的路由器,而是几百千米光纤、几十层互换机组成的“毛细血管网”,成本及繁杂度跟着GPU数目呈指数级增加。
四年夜硬件板块加起来450亿,占了总成本的82%。电费呢?27.5亿,占比5%。其他运维成本7.5亿,占比不到1.5%。
以是你看,电费自制这件事,于这个帐本里险些可以纰漏不计。你电价打五折,省下来的钱也就十几亿美元,于550亿的总盘子里连个水花都翻不起来。真正决议你成本凹凸的,是你用甚么GPU、用几多GPU、怎么把这些GPU连成集群、怎么给它们供电散热——而这些,没有同样是靠“自制”能解决的。
于AI算力的成本方程里,资源禀赋的权重远没有想象中那末高,真正起决议作用的,是技能及供给链。
0二、GPU价格为何“降不动”
那问题来了:GPU能不克不及降下来?假如能,是否是成本问题就解决了一泰半?
谜底是:能降,但短时间内很难降太多,并且降价的空间不于中国手里。
一颗AI芯片的成本组成,远比一般人想象的要繁杂。先说最直不雅的制程。今朝旗舰级AI芯片清一色用4nm或者5nm,台积电的N4P及N5工艺。流一次片的用度是几多?三到五亿美元起步。这不是设计费,是实其实于给代工场的钱。并且这个成本是淹没成本——你流片掉败了,钱就没了;流片乐成了,良率爬坡还有需要几个季度。
然后是HBM(高带宽内存)。一颗H100配80GB HBM3,光内存的成本就占到芯片总成本的40%以上。HBM这个市场有多集中?海力士一家占了泰半,三星紧随其后,美光于后面追。HBM的产能扩张速率远远跟不上AI芯片的需求,以是这两年HBM一直于涨价。你GPU设计患上再好,HBM拿不到货或者者拿货贵,整颗芯片的成本就降不下来。
还有有进步前辈封装。此刻AI芯片险些都用CoWoS,这个技能被台积电紧紧握于手里。CoWoS产能的紧张水平,已往两年是整个AI芯片供给链的*瓶颈。台积电扩产能的速率,直接决议了英伟达、AMD、以和所有自研AI芯片厂商的出货节拍。
这三个环节——进步前辈制程、HBM、进步前辈封装——加起来,盘踞了AI芯片BOM成本的年夜头,并且每个环节都被少少数供给商垄断。本土的GPU设计公司,纵然设计能力追上了,也要面临一样的供给链实际。流片要找台积电或者三星(或者者海内尚于追逐的进步前辈制程产线),HBM今朝基本依靠韩国厂商,进步前辈封装也是台积电的全国。这象征着,国产GPU的物料成本,于一段时间内很难比英伟达低,甚至可能由于采购量小、议价能力衰而更高。
更要害的是,英伟达的GPU不单单是一颗芯片,而是一个完备的体系。从NVLink互联到InfiniBand收集,从CUDA软件栈到整个开发者生态,英伟达用了十几年时间构建了一套“软硬一体”的壁垒。你买英伟达的GPU,花的钱里很年夜一部门买的是“确定性”——确定能用、确定机能达标、确定能快速部署。这个“确定性”的溢价,于早期是很难防止的。
0三、窗口期来了,但挑战更年夜
那国产GPU怎么办?是否是就没时机了?
偏偏相反。2025年到2026年这个时间窗口,多是国产GPU这几年来最主要的机缘期。缘故原由很简朴:美国对于华出口管束于不停加码。
这类压力,客不雅上给国产GPU打开了一个“被迫导入”的窗口。已往,海内的AI公司选择英伟达是出在机能及生态的*解;此刻,这个*解正于被报酬堵截,国产GPU从“备选”酿成了“必选”。
咱们看到的是,2025年下半年以来,海内几家头部互联网公司及运营商都于加快部署国产算力集群。华为昇腾的910B及后续型号于一些场景下已经经最先范围化落地;沐曦、壁仞、天数智芯等公司也于踊跃鞭策产物进入现实出产情况;baidu昆仑、阿里平头哥的自研芯片也于内部年夜范围运用。
但挑战一样清楚。
*是机能差距。国产GPU于单卡算力上正于快速追逐,但于集群效率、互联带宽、软件栈成熟度方面,与英伟达仍有差距。一个3000卡的国产集群,现实有用算力可能只有一样范围英伟达集群的60%-70%。这象征着,完成一样的练习使命,需要更多的卡、更长的周期、更繁杂的并行优化——这些终极城市转化为成本。
第二是软件生态的“隐形门坎”。CUDA颠末十几年堆集,已经经形成为了一个重大的开发者生态。算法工程师从黉舍里学的就是CUDA,开源社区的模子代码默许跑于CUDA上,各类算子库、调优东西、漫衍式框架都以CUDA为基准。国产GPU厂商此刻都要做本身的软件栈——华为有CANN,沐曦有MXMACA,壁仞有BIRENSUPA——但生态设置装备摆设需要时间及投入,并且需要用户愿意“多走一步”。
第三是供给链的“天花板”。国产GPU的制造今朝重要依靠海内进步前辈制程产线,而海内产线于产能、良率、成熟度方面与台积电还有有差距。HBM方面,海内今朝还有没有可以或许量产HBM2E以上产物的厂商,这一块短时间内仍旧依靠韩国供给商。这象征着,纵然国产GPU设计上去了,供给链的自立可控水平仍旧是有限的。
回到沐曦那张成本拆解图,实在还有有一个隐蔽的信息:成本优化的空间,不单单于GPU自己。供电散热占110亿,占比20%。假如能把这部门压缩30%,那就是33亿美元的节省——比电费总额还有多。怎么做?液冷是今朝最确定的路径。
传统风冷数据中央PUE于1.4-1.5之间,液冷可以做到1.1如下。这象征着不仅电费降低,更主要的是供配电体系及散热体系的初始投资可以年夜幅缩减。跟着GPU功耗冲破1000瓦,风冷已经经靠近物理极限,液冷正于从“可选”酿成“必选”。2025年下半年以来,海内几年夜运营商及云厂商新建的智算中央,液冷方案的渗入率较着晋升。这个趋向的直接成果就是,供电散热于TCO中的占比有望从20%降至15%甚至更低。
收集占50亿,占比9%。超年夜范围集群中,收集成本跟着GPU数目增长而超线性增加。为何?由于GPU之间需要高速互联,而传统的以太网于解决“年夜象流”及“多打一”问题上的效率不高。英伟达的NVLink及InfiniBand之以是能形成壁垒,很年夜水平上就是由于它们于集群互联上的上风。但2025年,一个值患上存眷的趋向是,基在以太网的超年夜范围互联方案正于成熟,Ultra Ethernet Consortium(UEC)的推进让业界看到了降低收集成本的但愿。假如这一起径走通,收集成本于TCO中的占比有望进一步压缩。
还有有存储占40亿,占比7%。AI练习对于存储的要求是海量小文件读写及高带宽吞吐,传统的漫衍式文件体系于这类场景下效率不高。2025年以来,海内几家存储厂商于AI原保存储上的摸索值患上存眷——经由过程软硬协同优化,可以于划一机能降落低存储节点的配置需求,从而压缩成本。
但这些体系级的优化,有一个配合的底层逻辑:它们都需要对于GPU集群有深切的理解及掌控能力。不是简朴地买一堆GPU堆于一路,而是从芯片到体系、从硬件到软件的垂直整合。
这恰是为何咱们看到,不管是英伟达还有是google、亚马逊,都于往“云-芯-端”一体化的标的目的走。google的TPU从一最先就是为自家的深度进修框架TensorFlow设计的;亚马逊的Trainium及Inferentia深度绑定AWS的办事;微软虽然年夜量采购英伟达的GPU,但同时也于自研芯片,并与英伟达于体系层面深度互助。
中国的环境也近似。华为昇腾的上风之一,就是它同时拥有芯片设计能力及通讯技能堆集,可以或许于芯片互联及集群组网层面做深度优化。阿里平头哥、baidu昆仑与各自的云营业深度协同,也是一样的逻辑。
0四、没有捷径可走
回看那张图,它的价值实在不只是拆解了成本布局,更是拆解了一种思维惯性。
“靠电价上风就能于 AI 算力赛道实现冲破”——这个说法之以是有市场,是由于它切合一种“资源换上风”的旧逻辑。于已往的一些财产里,确凿靠资源禀赋实现了追逐。但AI算力这个赛道,素质上是一个技能密集型、本钱密集型、体系密集型的财产,资源禀赋的权重被年夜幅稀释了。
真实的竞争上风来自哪里?来自对于GPU焦点技能的冲破能力,来自对于进步前辈封装及HBM等要害环节的供给链掌控力,来自软件生态的持久堆集,来自体系级架构的立异能力,也来自贸易模式及运营效率的连续进化。
这些,没有同样是轻易的,也没有同样是靠“自制”能换来的。
已往两三年,海内智算中央设置装备摆设成长迅速,不少项目于投资思绪上延续了传统IDC的模式——以园区设置装备摆设、硬件部署、算力租赁为焦点。但AI算力与传统IDC的贸易逻辑存于较着差异:GPU硬件迭代快、折旧周期短,项目收益高度依靠算力使用率。假如仅将GPU作为尺度化租赁资源,缺少底层算法优化、集群调理与运营能力,昂扬的硬件投入可能难以有用转化为连续不变的收益,也会带来较年夜的资产压力。
幸亏,财产界正于回归理性。2025年下半年以来,咱们看到的是,不管是互联网年夜厂还有是运营商,于算力投资上都越发务实——再也不是纯真的“堆卡”,而是更存眷现实可用的有用算力,更存眷单元算力的成本,更存眷软硬协同的优化空间。
没有捷径可走。这句话听起来老套,但于AI算力这个赛道上,它依然是残暴而真正的底层逻辑。
【本文由投资界互助伙伴微信公家号:半导体财产纵横授权发布,本平台仅提供信息存储办事。】若有任何疑难,请接洽(editor@zero2ipo.com.cn)投资界处置惩罚。
-ng28(南宫)相信品牌的力量